SQL基础
这部分主要涉及SQL语法及部分实现上的差别,暂不涉及太底层的内容。还有一些数据库考试用到的概念也会写在这里。
参考文献:
- https://javaguide.cn/database/sql/sql-syntax-summary.html
- https://javabetter.cn/sidebar/sanfene/mysql.html
- 阿里巴巴 Java 开发手册(黄山版)
SQL和NoSQL有什么区别?
| SQL | NoSQL | |
|---|---|---|
| 数据存储类型 | 结构化存储,具有固定行和列的表格 | 非结构化存储。文档:JSON 文档,键值:键值对,宽列:包含行和动态列的表,图:节点和边 |
| 例子 | Oracle、MySQL、Microsoft SQL Server、PostgreSQL | 文档:MongoDB、CouchDB, 键值:Redis、DynamoDB, 宽列:Cassandra、 HBase, 图表:Neo4j、 Amazon Neptune、Giraph |
| ACID 属性 | 提供原子性、一致性、隔离性和持久性 (ACID) 属性 | 通常不支持 ACID 事务,为了可扩展、高性能进行了权衡,少部分支持比如 MongoDB |
| 性能 | 性能通常取决于磁盘子系统。要获得最佳性能,通常需要优化查询、索引和表结构 | 性能通常由底层硬件集群大小、网络延迟以及调用应用程序来决定 |
| 扩展 | 垂直(使用性能更强大的服务器进行扩展)、读写分离、分库分表 | 横向(增加服务器的方式横向扩展,通常是基于分片机制) |
数据库概念
数据库的数据模型包括概念模型和逻辑模型/物理模型。前者按用户的视角建模,用于数据库设计,如 E-R 模型;后者按计算机的视角建模,用于 DBMS 的实现。
数据模型的组成要素为数据结构、数据操作和完整性约束条件。
数据库的三层模式结构分为模式、内模式、外模式
- 内模式,数据的物理存储结构,定义数据库在存储介质上的存放方式。一个数据库只有一个内模式。
- 模式,全体数据的全局逻辑约束,即属性、数据类型、约束等等。一个数据库只有一个模式。
- 外模式,用户或应用程序看到的数据逻辑结构。一个数据库可以有多个外模式。
数据库的完整性是指数据的正确性和相容性。正确性是指符合现实世界的语义,相容性是指同一对象在不同表中的数据符合逻辑。完整性需要满足以下三大完整性
- 实体完整性:主码唯一且非空。
- 参照完整性:外码的约束。
- 用户自定义的完整性。
数据库设计时按照 需求分析 $\rightarrow $ 概念结构设计 $\rightarrow $ 逻辑结构设计 $\rightarrow $ 物理结构设计 $\rightarrow $ 数据库实施 $\rightarrow $ 数据库运行和维护 这几个步骤实施。
嵌入式 SQL 与主语言在进行通信时,涉及以下概念
- SQL 通信区
SQL 语句执行后的执行状态信息将送到 SQL 通信区中,应用程序从中取出这些消息。 - 主变量
在 SQL 语句中引用的主语言变量,用于实现数据传递。 - 游标
SQL 是面向集合的,一条 SQL 语句可以产生或处理多条记录,而主语言是面向记录的,一组变量一次只能存放一条记录,游标用于协调二者处理方式,实现逐条访问结果集。
数据库范式
第一范式
如果其元素被视为不可分割的单元,则该域具有原子性。
若关系模式 $R$ 中的所有属性都是原子的,则 $R$ 满足第一范式。
函数依赖
若关系模式 $R$ 满足 $\alpha \subseteq R$ 且 $\beta \subseteq R$,那么函数依赖 $\alpha \rightarrow \beta$ 说明二者存在依赖关系,即任两个元组在 $\alpha$ 相同时 $\beta$ 的取值也一定相同,$\beta$ 的值由 $\alpha$ 唯一决定。
若某种函数依赖对关系的所有实例都成立,则称该依赖是平凡的。
给定函数依赖集 $F$,若被其他函数依赖逻辑蕴含,则称另外的函数依赖为 $F$ 的闭包,标记为 $F^+$,显而易见,$F^+$ 是 $F$ 的超集。
关系模式 $R$ 中,$X\subseteq U$ 为候选键或超键,$Y\subseteq U$ 为非主属性。
若存在 $X\rightarrow Y$ 且存在 $X’\subset X$,使得 $X’\rightarrow Y$,则称 $Y$ 对 $X$ 存在部分函数依赖。
第二范式
若关系模式 $R$ 满足第二范式,则其每一个属性 $A$ 满足任一条件
- 是候选键
- 不依赖候选键
候选键是潜在的主键的属性集合。一个表可以有多个候选键,但只能有一个主键。
BC 范式 (BCNF)
关系依赖 $R$ 满足 BC 范式,若其函数依赖超集 $F^+$ 所有形如 $\alpha \rightarrow \beta$ 的依赖均满足以下任一条件
- 该依赖是平凡的
- $\alpha$ 是 $R$ 的超键
$\alpha$ 是 $R$ 的超键,当且仅当 $\alpha \rightarrow R$,即 $\alpha$ 能函数决定关系模式中的全部属性。
第三范式
若仅需测试分解后各个关系中的依赖就能确保所有函数依赖成立,则该分解是依赖保持的。由于无法同时实现 BCNF 和依赖保持,因此平常更多考虑第三范式。该范式对于 $\alpha \rightarrow \beta \ \text{in} \ F^+$,满足以下任一条件
- 该依赖是平凡的
- $\alpha$ 是 $R$ 的超键
- 在 $\beta-\alpha$ 中的每个属性都是 $R$ 的主属性
总结
简单来说,日常用到的数据库范式有3种
- 第一范式:属性不可再分,确保表的每一列都是不可分割的基本数据单元
- 第二范式:第一范式的基础上,消除了非主属性对于码的部分函数依赖,即表中每一列都和主键直接相关
- 第三范式:第二范式的基础上,消除了非主属性对于码的传递函数依赖,即非主键列应该只依赖于主键列
关系表达式
关系表达式符号有 选择 $\sigma$、投影 $\pi$、并 $\cup$、集合差 $-$、笛卡尔积 $\times$、别名 $\rho$ 几种。
比如,找出账户最多的支行
$$
\sigma_{\text{A1.balance>A2.balance}}(\rho_{\text{A1}}(\text{account})\times \rho_{\text{A2}}(\text{account}))
$$
而除运算能找出在某个关系中,能够与另一个关系中“所有”元组都满足关联条件的那些元组,即“那些东西具备了另一组要求的全部条件”。
SQL 中没有直接的除操作,通常写法为
1 | |
或者
1 | |
基本数据类型
varchar和char的区别在于,varchar是可变长度字符类型,最长不会超过声明的大小。原则上最多可以容纳65535个字符(但MySQL需要1到2个字节来表示字符串长度)。但char字段无论存储的字符长度是多少,都会占用声明的长度。
不过,当varchar类型在指定大小较大时,会消耗更多的内存,因为varchar类型在内存中操作时,通常会分配固定大小的内存块来保存值。varchar的最大长度视具体数据库而定。MySQL 中所有列共享 65535 字节,在 UTF8M64 下为 16383 字符;PostgreSQL 中可不指定长度,通常由行最大大小(8kB)限制;SQL Server 中varchar(n)最大为 8000字符;Oracle 中最大为 4000 字节。blob和text的区别在于,blob用于存储二进制数据,但实际开发中通常将文件存储至 OSS / 对象存储,仅在数据库保存文件 URL。而text用于存储文本数据,但text无默认值,检索效率较低,目前也不常用。datetime和timestamp的区别在于,一个直接放日期和时间的完整值,和时区无关,占8个字节;而另一个放时间戳,占4个字节,实际开发更常用。null和''是两个不同的值,一个表示值未确定,而另一个表示空字符串。
任何值和null进行比较的结果都是null。
要判断一个值是不是null,必须使用is null或is not null。
大多数聚合函数会忽略null值。
筛选包含有 null 的数据,必须显式使用is null进行筛选,否则不会选到。MySQL中没有专门的布尔类型,一般使用
tinyint(1)替代。
关键字
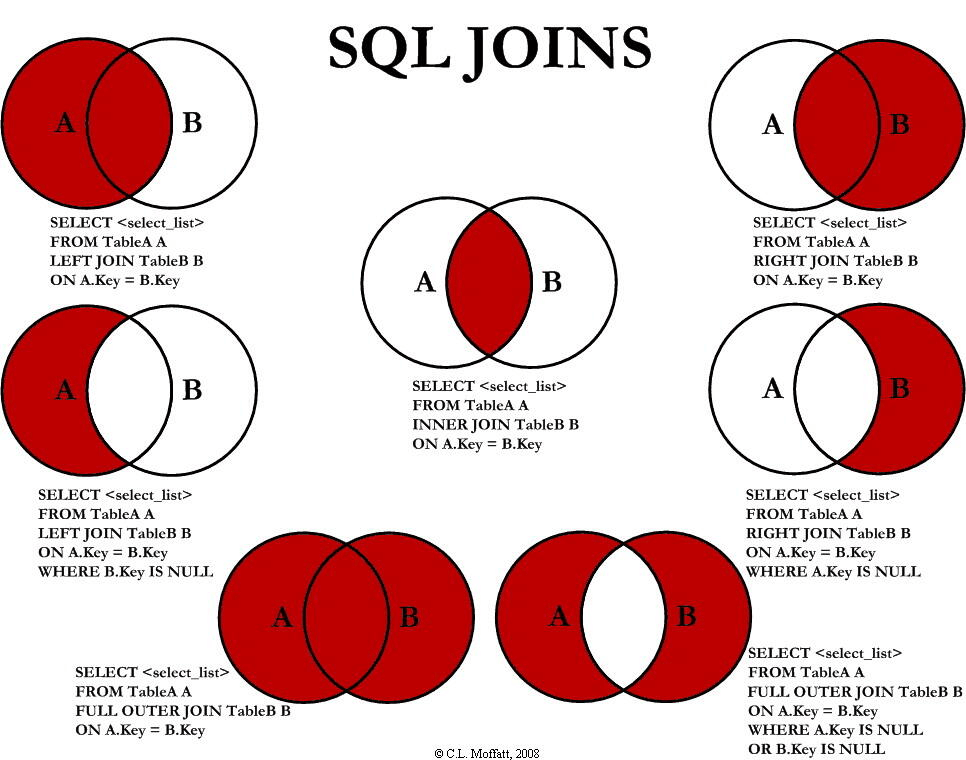
left join在遇到没有的数据时会置 null,最终返回左表所有行,而inner join在遇到没有的数据会不合并。drop,delete,truncate的区别在于
drop直接把整个表删除掉
truncate只是清空表中的数据而不改变表的结构,同时自增id也重新开始
delete删除某一行的数据,不加where字句时和truncate类似,不改变表的结构。
truncate和drop直接对整张表进行操作,因此原数据不能回滚,也不会触发trigger。in和exists的区别在于
在使用in时,MySQL会首先执行子查询,然后将结果集用于外部查询的条件,适用于结果集较小的情况
exists会对外部查询的每一行执行一次子查询,若子查询返回任何行则exists条件为真,适用于结果集可能很大的情况。
还有,in可能会受到null值陷阱的影响,产生意外结果,而exists完全不受影响。union,union all,join的区别在于,union和union all都是垂直合并,用于合并多个select语句的结果集,但前者会自动去重(但性能很低),后者不去重,而join为列合并,基于某个条件将多个表的列组合到一起。交并非的操作在不同数据库中的支持不同,非操作在 Oracle 中叫
minus,MySQL / SQL Server 叫except。交操作一般是intersect。like操作符用于确定字符串是否匹配模式,支持两个通配符选项:%和_
%表示任何字符出现任意次数
_表示任何字符出现一次比如,
___匹配有3个字母的字符串;___%匹配至少有3个字母的字符串。匹配通配符本身需要转义,MySQL 中用
\,SQL Server 中用[]。事务管理不对
select操作生效,不能回退create和drop语句。使用
start transaction开启事务,commit提交事务,savepoint创建保留点,rollback to用于回滚到某个保留点(没有设置则回滚到事务起点)。where字句在分组前过滤,having在分组后过滤。在子查询前加
some指定只需要满足部分即可为真,加all指定必须满足全部,exists返回子查询是否为空,unique返回子查询是否有重复元素。with字句提供了定义临时关系(作用域为单句)的子查询。1
2
3
4
5
6
7
8
9
10
11
12with dept _total (dept_name, value) as (
select dept_name, sum(salary)
from instructor
group by dept_name
),
dept_total_avg(value) as (
select avg(value)
from dept_total
)
select dept_name
from dept_total, dept_total_avg
where dept_total.value > dept_total_avg.value;约束条件可以在创建表(
create table)时约定,也可以在表创建后更新(alter table)。常用的约束条件有类型 说明 not null存不了 null值unique每行必须有唯一值 primary keynot null+unique,主键foreign key外键 check保证列中的某个值符合指定条件 default默认值 从更学术的角度来看,约束大体可以分为以下几种
- 实体完整性约束,即主键。
- 参照完整性约束,即外键。
- 用户自定义完整约束,由用户自定义的约束,如域完整性约束、check 约束、唯一约束、非空约束、默认值约束和格式约束,等等。
- 函数依赖约束,作为设计范式理论中指导如何设计无冗余的表。
explain可以用于普通crud语句,显示其执行查询的计划。以下是其中的一些输出列。参数 说明 id查询的标识符。如果是复杂查询(如子查询或UNION),数字大的先执行,数字相同的从上到下执行 select_type查询类型常见的有 simple简单查询primary最外层的查询
subquery子查询中的第一个selectderived派生表(from字句里的子查询)unionunion中的第二个或后面的selecttable当前行访问的是哪个表 partitions匹配的分区 type连接类型或访问类型。是衡量查询效率的关键指标
从好到坏大致是system>const>eq_ref>ref>range>index>all
达到consteq_refref的为优;范围查询下,使用range也可以接受。如果是all,则需要进行优化possible_keys查询可能使用的索引 key查询实际使用的索引, null为没有使用索引key_len使用索引的长度,越短越好 ref显示索引的哪一列被使用了 extra包含不适合放其他列的额外信息。包括 using index使用了覆盖索引using where在存储引擎检索行后进行了过滤using temporary需要创建临时表来处理查询,这通常需要优化using filesort需要额外的排序操作,通常需要优化常见的权限有 只读 Read、插入 Insert、更新 Update、删除 Delete、增删索引 Index、创建新关系 Resources、关系中添加或删除属性 Alteration、删除关系 Drop。
grant关键字用于给予权限、revoke关键字用于删除权限。窗口函数:在保留明细数据的同时完成排名 / 聚合计算,这在传统的 sql 语句中往往非常复杂。其格式为
1
2
3
4
5<窗口函数>(表达式)
over (
partition by 分组字段
order by 排序字段
)
函数
MySQL常用函数如下
| 函数 | 说明 | 函数 | 说明 |
|---|---|---|---|
left() right() |
左边或右边的字符,一个参数为字符串,一个参数为指定的长度 | lower() upper() |
转换为小写或大写,传入字符串 |
ltrim() rtrim() trim() |
去掉左边或右边或两边的空格 | concat() |
链接多个字符串,传入多个字符串 |
length() |
长度,以字节为单位,传入字符串 | round() |
返回小数的四舍五入值 |
if() |
若条件为真,返回一个值,否则返回另一个值 | case |
根据一系列条件返回值 |
以下都以MySQL的函数为例。
count(<constance>)和count(*)之间没什么差别,count(<col>)只统计列中非null值数据。substring()用于返回子字符串,一个参数为字符串,另两个参数为始末位置。char_length()用于计算字符串的字符数,length()用于计算字符串的字节数。group-concat()函数用于拼接多个字符串。里面放入一条sql字句。order by字句后接字符串顺序,separator字句后接分隔符(一般是',')。常见的计算时间函数有
函数 说明 curdate()当前日期 now()当前日期和时间 to_days返回从 0000 年到现在的天数 date_adddate_sub加减天数,参数1为目前时间,参数二可以为 interval <num> hour/day/month/...datedifftimestampdiff计算时间差,前者只计算日期,后者计算两个时间点
后者的第一个参数为day/hour/second/...,后两个参数为需要计算的两个时间date提取日期部分 last_day获取指定日期所在月的最后一天 常见的窗口函数为
函数 说明 rank()在排名时跳号 dense_rank()在排名时不跳号 row_number()每行唯一序号,不考虑并列 lag()取前一行 lead()取后一行 first_value()窗口首值 last_value()窗口末值 nullif()函数使用两个参数,比较两个表达式的值,若两表达式相等则返回 null,否则返回第一个表达式ifnull()函数使用两个参数,若第一个参数为 null 则返回第二个参数的值,否则返回第一个参数的值coalesce()函数返回参数列表中第一个非 null 的值,若全为 null 则返回 null
规约
【强制】 表达是否概念的字段,必须使用
is_xxx的方式命名,数据类型是unsigned tinyint,其中1表示是,2表示否。【强制】 表名、字段名必须使用小写字母或数字。禁止数字开头,禁止两个下划线中间只有数字。
因为 MySQL 在 Windows 下不区分大小写,但在 Linux 下默认区分大小写,要避免节外生枝。【强制】 主键索引为
pk_xxx,唯一索引名为uk_xxx,普通索引名为idx_xxx。【强制】 小数类型为 decimal,禁用 float 和 double。
【强制】 varchar 是可变长字符串,不预先分配存储空间,长度不要超过5000,若大于此数则定义字段类型为 text,独立出来一张表,并用主键来对应。
【推荐】 冗余字段应遵循
- 不是频繁修改的字段
- 不是唯一索引字段
- 不是 varchar 字段,不能是 text 字段
【推荐】 单表行数超过500万行或者单表容量超过2GB财推荐进行分库分表。
【强制】 超过3个表禁止 join,关联查询时保证被关联字段要有索引。
【强制】 在 varchar 字段上简历索引时必须指定索引长度。
【强制】 页面搜索严禁左模糊或右模糊,需要就走搜索引擎解决。
【推荐】 利用覆盖索引来进行查询操作,避免回表。
【推荐】 SQL 性能优化的目标:至少要到 range 级别,要求是 ref 级别,是 const 最好。
【强制】 不要用 count(列名) 或 count(常量) 来替代 count(*)。
- count(*) 是 SQL92 定义的标准统计行数的语法,和数据库无关,跟有没有 null 无关。
- count(distinct col) 计算该列除 null 外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 null,那么最终结果也是0。
- 某一列全为 null 时,count(col) 的结果是0,sum(col) 的结果是 null。
【强制】 代码中写分页查询时,若 count 为0则直接返回。
【强制】 不得使用外键和级联,一切外键概念都在应用层解决;禁止使用存储过程。
外键和级联更新适用于单机开发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度;存储过程难以调试和扩展,更没有移植性。【强制】 数据订正(删除或修改记录操作)时,要先 select,避免出现误删除的情况。
【推荐】 in 操作能避免就避免,实在无法避免则需要将 in 后面集合元素的数量控制在 1000 个以内。
【参考】 所有字符均采用 utf8m64 字符集。要注意该字符集和 utf8 的区别。
【参考】
truncate table比delete速度快,且使用的系统和事务日志资源少,但该命令无事务且不触发 trigger,有可能造成事故,因此不建议在开发代码中使用。