数据库底层 - 2
锁的类别
全局锁
锁整个数据库。适合全库备份等场景。
表锁
锁整张表。适合读多写少,全表扫描或表结构更改的场景。InnoDB 中无索引的 update 或 delete 可能会导致锁升级为表锁。
意向锁
表示事务打算对表中某些数据加锁,但不会直接锁定。比如在实行 select for update 操作时,会先在表上加一个意向锁,然后在目标行上加排他锁。该锁由 InnoDB 自动管理。当事务需要添加行锁时,会先在表上添加意向锁。这样当要添加表锁时,可以通过查看表上的意向锁,快速判断是否有冲突。
意向锁主要用于协同其他锁进行工作。避免为了添加表锁而不得不扫描全表的情况。而共享锁允许多个事务同时加从而读取同一数据。但排他锁和其他共享锁或排他锁均互斥。
| 当前持有的锁 | X(排他锁) | S(共享锁) | IX(意向排他) | IS(意向共享) |
|---|---|---|---|---|
| X | 否 | 否 | 否 | 否 |
| S | 否 | 是 | 否 | 是 |
| IX | 否 | 否 | 是 | 是 |
| IS | 否 | 是 | 是 | 是 |
还存在 SIX 这种“意向共享 + 排他锁”,用于“既要读整张表,又要修改某些行”,与其他的锁都互斥。
行锁
行锁的底层是通过给索引加锁实现的,InnoDB 只有在通过索引条件检索数据时,才能使用行级锁。
- 记录锁
这是行锁最基本的表现形式,当我们使用唯一索引或主键做等值查询时,MySQL会为该记录自动添加排他锁,禁止其他事删除务或修改锁定记录 - 间隙锁
进行范围查询时,锁定记录间的“间隙”(无数据的区间),防止其他事务在该范围内插入新纪录,防止幻读
在执行for updatelock in share mode等加锁语句,且查询条件是范围查询时,就会自动加间隙锁 - 临键锁
这是前两者的结合体,既锁本身又锁它前面的间隙.
该锁区间是左开右闭。在 InnoDB 默认的事务隔离级别(可重复读)下, 行锁默认就是临键锁.
事务
事务遵循 ACID 特性,即原子性、一致性、隔离性和持久性。
- 原子性
Atomicity
要么全部完成,要么全部不完成。 - 一致性
Consistency
确保事务从一个一致的状态转移到另一个一致的状态。
例如银行的转账中,无论转没转成功,最后转账双方的总金额应该是不变的。 - 隔离性
Isolation
并发执行的事务是彼此隔离的,一个事务的执行不会被其他的事务干扰。
隔离级别详情需要看下面内容 - 持久性
Durability
事务一旦提交,它对数据所做的更改就是永久性的。
隔离级别
腾讯微信支付 - 实习, 一面.
SQL标准定义了四种事务隔离级别,用来平衡事务的隔离性和并发性能
- 读取未提交,允许读取尚未提交的数据变更。
- 读取已提交,允许读取已提交的数据。Oracle 或 SQL Server 默认的隔离级别。
- 可重复读,对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己修改。MySQL InnoDB 的默认隔离级别。
- 可串行化,所有事务依次逐个执行,这样事务间就不会造成干扰。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读取未提交 | 是 | 是 | 是 |
| 读取已提交 | 否 | 是 | 是 |
| 可重复读 | 否 | 否 | 是,但在 InnoDB 中很难发生 |
| 可串行化 | 否 | 否 | 否 |
不同的隔离级别可能会产生不同的不一致问题
- 脏读,及一个事务读到了另一个尚未提交的事务修改的数据。该数据可能会回滚,因此可能根本不存在。那么第一个事务读到的数据就是“脏”的。
- 不可重复读,在同一个事务中,两次读取同一条记录,得到的结果不一致。也就是说,在事务执行期间,它正在处理的数据被其他已提交的事务修改了。
- 幻读,在同一个事务中,两次执行相同的条件查询,第二次查询看到了第一次查询没看到的新的“幻影”行。也就是说,在事务执行期间,有其他 已提交的事务插入了新的、满足查询条件的记录。
不可重复读的重点在于修改了已有的行,幻读的重点在于新增了原本不存在的行。
在可串行化调度中,多个事务的并发执行结果为这些事务按某种次序串行化执行的结果。要实现这个效果,就必须满足两段锁协议 (2PL)
- 获得封锁,在对任何数据进行读写操作前,事务首先要获得对该数据的封锁。
- 释放封锁,在释放一个封锁后,事务不再申请和获得任何其他封锁。
MVCC
字节跳动, 中国交易与广告 - 实习, 一面
MVCC机制全称为 Multi-Version Concurrency Control (多版本并发控制)。它是通过在每个数据行上维护多个版本的数据来实现的。
当一个事务执行读操作时,它会使用快照读,读取该事务开始前的数据快照,这样,读操作就不会被写操作阻塞,反之亦然。
读操作分为两种:当前读和快照读。
- 快照读指事务在执行
select查询时,InnoDB不会直接读取当前最新数据,而是根据事务开始时生成的快照去判断每条记录的可见性,从而读取符合条件的历史版本 - 当前读指事务在进行更新、插入和删除操作时,其本质上也要进行读操作。为了保证修改的是最新的数据,并防止并发冲突,InnoDB必须读取最新版本的数据并加锁。
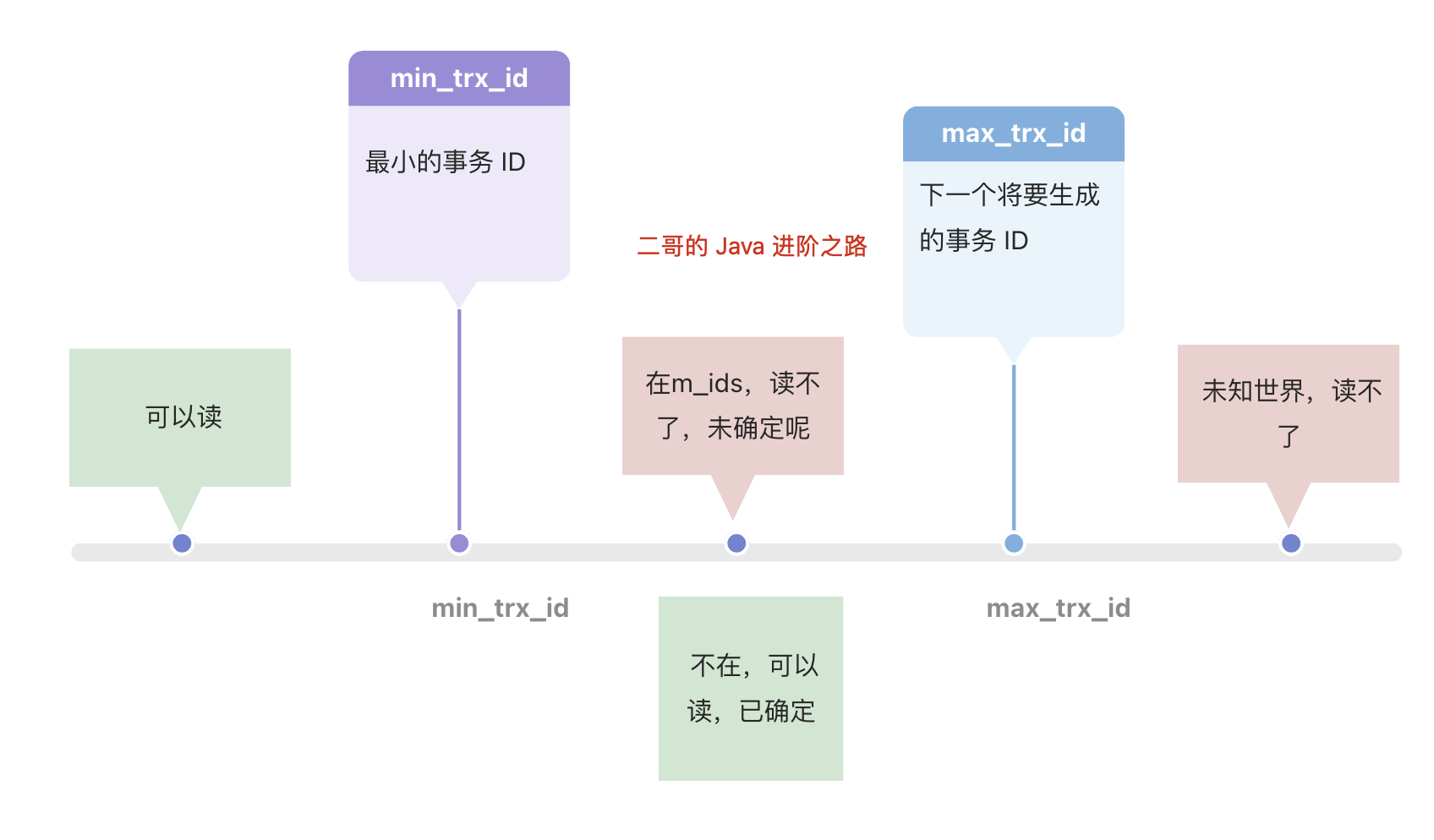
在不同的隔离级别下
- 读已提交
每一次执行select语句时,都会重新生成一个新的快照。因此它能读取到最新已提交的数据,避免了脏读,但无法避免不可重复读。 - 可重复读
只有第一次执行select语句时才会生成一个快照,并且这个快照贯穿整个事务的始终。因此事务中后续的所有读操作都是在同一个快照下进行,避免了不一致问题。 - 其他的级别不需要MVCC机制
MVRC
Oracle 中使用的多版本控制工具。
修改数据时,旧数据存入回滚段(Undo Segment),数据行头记录事务信息。
查询时:
- 若数据未被修改,则直接读
- 数据被修改且事务未提交 / 在查询后提交 → 从回滚段重建历史版本
因此 Oracle 默认隔离级别为读已提交。
高可用
读写分离
字节跳动, 中国交易与广告 - 实习, 一面
可以对数据库的读写操作分散到不同的节点上,一个节点为主,负责写操作,多个从。负责读操作。应用层通过中间件(小型项目自己处理,中型项目通过spring + 多数据源插件,AOP 注解自动路由,大型项目通过中间件,如MyCat、Atlas、shardingsphere 或 MySQL Router)进行代理,自动路由请求。
主库将数据变更通过 binlog 同步到从库,从而保证数据一致性。
- 主库将数据变化写入 binlog
- 从库链接主库
- 从库会创建一个 IO 线程向主库拉更新的 binlog
- 主库会创建一个 binlog dump 线程来发送 binlog,从库中的 IO 线程负责接收
- 从库的 IO 线程将接收的 binlog 写入到 relay log 中
- 从库的 SQL 线程读取 relay log 同步数据到本地,即再执行一遍 SQL
但是同步过程毕竟是异步的, 在接收 binlog 的过程中可能会造成主从延迟,对某些业务场景可能无法容忍,一般有三种解决方案。
- 对一致性高的数据走主库查询
- 对非关键业务允许短暂数据不一致,在业务端阻塞
- 采用半同步复制,主库在事务提交时,要等至少一个库确认收到 binlog(但不要求执行完成)才算提交成功
造成主从延迟的原因可能有很多种,例如从库机器性能比主库差,从库处理请求太多,事务过大,从库太多,网络延迟,等等。
Canal
阿里国际数字商业集团, AI 应用研发工程师 - 实习, 一面
Canal 用于伪装 MySQL 从库, 用于订阅 binlog.
在Canal 宕机后
- 若 Canal 挂掉前已经把消费到的 binlog 位置存在本地了, 那么重启后, 就会自动从上次消费到的 binlog 位置继续拉取.
- 若 Canal 挂掉时, MySQL 的 binlog 已经被 purge 删除了, Canal 找不到对应的位点, 那么就无法增量同步, 就只能全量同步.
为了尽量避免全量同步, Canal 需要合理配置 binlog 保留时间, 一般保留 3~7 天时间, 而且不能手动 purge, 还要把消费到的位置存下来.
分库分表
分库分两种
- 水平分库,一个表按一定的规则拆分到不同的库中
- 垂直分库,按照业务模块将不同的表拆分到不同的库中
分表也可以垂直分表或水平分表。其中水平分表一般在单表数据达到500万级,或者数据库占用空间过大时,就可以考虑。
数据的分片有以下几种方案
- 哈希分片:求指定分片键的哈希,然后根据哈希值确定数据应该被放置在哪个表中
适合随机读写的场景,但对动态伸缩(动态新增表或库)不友好 - 范围分片:按照特定的范围区间来分配数据
适合经常进行范围查找且数据分布均匀的场景,不适合随机读写的场景 - 映射表分片(路由分片):使用一个单独的映射表来存储分片键和分片位置的对应关系。映射表的策略可以支持任何类型的分片算法
可以灵活调整分片规则,但需要维护额外的表,增加了查询的开销和复杂度
可以使用 ShardingSphere 插件来实现分库分表。
不停机扩容分为三个阶段
- 新旧库同时写入,确保数据实时同步;可以借助消息队列实现异步补偿,幂等避免重复写入。读操作仍然走旧库
- 通过某些脚本将旧库的历史同步到新库,关键业务在查询时同时查询新旧库,进行数据校验,确保一致性
- 确保新库数据一致性后,逐步将读请求切换到新库,然后下线旧库
分库分表不是分得越细越好,进行分库分表后
- 同一个数据库中的表分布在了不同的数据库中,导致无法使用join联表查询
- 若单个操作涉及多个数据库,那么数据库自带的事务就无法满足需求了,必须引入分布式事务
- 自增ID容易引发冲突,需要引入分布式ID,使用全局唯一方案