微服务系统组件 - 2
参考文献
- https://javaguide.cn/distributed-system/api-gateway.html
- https://javabetter.cn/sidebar/sanfene/weifuwu.html
- https://www.bilibili.com/video/BV1LQ4y127n4
- https://zhuanlan.zhihu.com/p/715997276
服务网关
API 网关是一种中间层服务器,用于集中管理、保护和路由对后端服务的访问。其功能主要包括请求转发+请求过滤,但小型要求不少,包括 请求转发、负载均衡、安全认证(对客户端请求进行身份验证并仅允许可新用户访问 api,并且还能够使用类似 RBAC 等方式来授权)、参数校验(支持参数映射和校验逻辑)、日志记录、监控告警、流量控制、熔断降级、响应缓存、响应聚合、灰度发布、异常处理、API 文档、协议转换、协议转换、证书管理,等等。
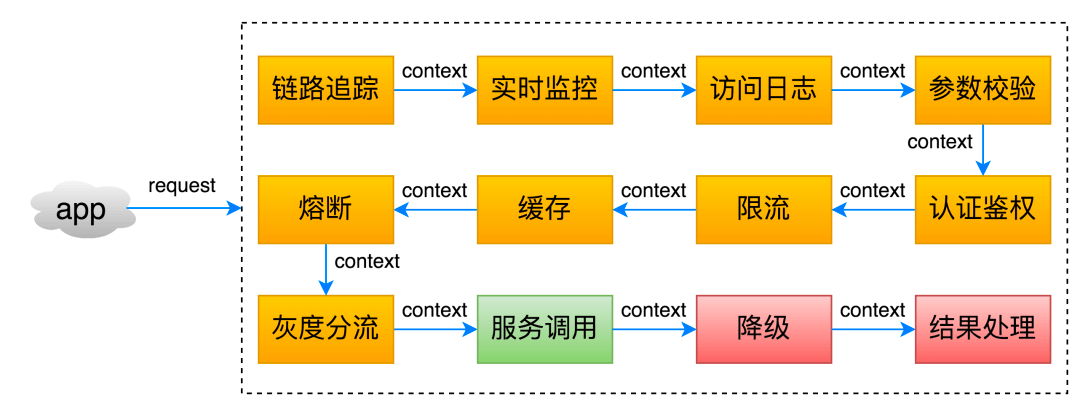
需要注意的是,网关中的校验不能当作安全性的唯一保证,需要有其他手段保证外来用户不能绕过网关。
Netflix Zuul
Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的网关服务,可以和 Eureka、Ribbon、Hystrix 等组件组合使用。Zuul 主要通过过滤器来过滤请求,从而实现网关的各种功能。
Zuul 1.x 基于同步 IO,性能较差,而 Zuul 基于 Netty 实现了异步 IO,性能得到了大幅改进。
Spring Could Gateway
这是属于 Spring Cloud 系统中的网关,基于 Spring WebFlux。Spring WebFlux 使用 Reactor 库实现响应式编程,底层是基于 Netty 实现的同步非阻塞 IO。
一般在网关服务中的配置类文件如下
1 | |
具体的流程为
- 路由判断,客户端的请求结束后,先经过 Gateway Handler Mapping 处理,在这里做断言判断,以映射后端的某个服务
- 请求过滤,请求到达 Gateway Web Handler,这里面有很多过滤器,组成过滤器链,这些过滤器可以对请求进行拦截和修改,比如添加请求头,参数校验等等
- 服务处理,后端服务器对请求进行处理
- 响应过滤,后端处理完结果后,返回给 Gateway 的过滤器再次处理
- 响应返回,经过过滤处理的结果返回给客户端
断言是指对某个表达式的真假判断,若为真则跳转到某个路由。基本的 Predicate 工厂为
| 名称 | 说明 | 实例 |
|---|---|---|
| After | 某个时间点后的请求 | After=2037-01-20T17:42:47 |
| Before | 某个时间点前的请求 | Before=2037-01-20T17:42:47 |
| Between | 某个时间段内的请求 | Between=2037-01-20T17:42:47, 2038-01-20T17:42:47 |
| Cookie | 请求必须包括某些 Cookie | Cookie=chocolate,ch.p |
| Header | 请求必须包括某些 header | Header=X-request-id,\d+ |
| Host | 请求必须是访问某个 Host | Host=**.somehost.org |
| Method | 请求必须是某种方式 | Method=GET,POST |
| Path | 请求路径必须符合指定规则 | Path=/red/** |
| Query | 请求参数必须包含某些参数 | Query=name |
| RemoteAddr | 请求者的 IP 必须是指定范围 | RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 | / |
要实现网关的动态路由,一般是通过 Nacos 动态配置来做。
网关过滤器有三种,分别是 默认过滤器、路由过滤器、全局过滤器。每一个过滤器都必须指定一个 int 类型的 order 值(可以是负数),order 值最小,优先级越高,执行顺序约靠前。在全局过滤器中,这个 order 可以通过注解或者实现接口的方式指定;而路由过滤器的顺序由 Spring 指定,默认是按照声明顺序从1指定。当过滤器的 order 值一样时,会按照 默认过滤器 > 路由过滤器 > 全局过滤器的顺序进行。
在 Spring Boot 项目中我们捕获全局异常只需要在项目中配置 @RestControllerAdvice 和 ExceptionHandler 即可。而在 Spring Cloud Gateway 中,比较常用的是实现 ErrorWebExceptionHandler 并重写其中的 handle 方法。
OpenResty
这个基于 Nginx + Lua,并发能力较好,但二次开发门槛较高。
Kong
这个基于 OpenResty,支持多种插件和扩展,可以满足不同的 API 管理需求。
APISIX
APISIX 是基于 OpenResty 和 etcd (使用 go 语言开发的分布式 key-value 存储系统,使用 Raft 协议做分布式共识) 的网关系统。与传统的 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务下的 API 管理。
链路追踪
通过链路追踪服务可以可视化追踪请求从一个微服务到另一个微服务的调用情况。常用的工具有
| 工具 | 特点 | 数据存储 | 适用场景 |
|---|---|---|---|
| Zipkin | Twitter 开源,轻量级 | 内存、MySQL、Elasticsearch 等 | 需要快速搭建、功能直接的分布式追踪 |
| Jaeger | Uber 开源,云原生项目 | Cassandra、Elasticsearch | 云原生环境,需要强大监控和事务分析能力的复杂微服务架构 |
| SkyWalking | 专为微服务混合云原生设计 | Elasticsearch、MySQL 等 | 以 Java 技术栈为主,希望获得全方位应用性能监控场景 |
| Spring Cloud Sleuth | Spring Cloud 生态的客户端工具,无缝整合 Zipkin / Jaeger | 需要依赖后端系统(如 Zipkin) | Spring Cloud 技术栈,简化代码中追踪信息的追踪和上报 |
Elasticsearch
Elasticsearch 用于在海量的数据中快速找到需要的内容,Elasticsearch 结合 kibana、Logstash、Beats,形成 elastic stack (ELK),广泛应用于日志分析,实时监控领域。
原理
OPPO 后端工程师 - 实习, 二面
ES 的底层基于倒排索引实现。
我们使用文档表示关系型数据库的每一条数据,使用词条 (term) 表示文档按照语义分成的词语(类似 Python 中 jieba 分词后的词语集合)。在关系型数据库中,文档中存储的是关键词列表,而在倒排索引中,我们用关键词存储文档列表。
例如,假设数据库中的数据为
| 武将 id | 武将名 | 武将描述 |
|---|---|---|
| 001 | “董卓” | “辅助型英雄,为自己的武将增伤并对敌人的武将减防” |
| 002 | “吕布” | “输出型英雄,主要打单体伤害” |
现在需要建立武将描述的倒排索引。因此此处的文本首先会被分析器处理
001: [“辅助”, “英雄”, “自己”, “武将”, “增伤”, “敌人”, “减防”]
002: [“输出”, “英雄”, “主要”, “单体”, “伤害”]
于是开始构建倒排索引
| 词条 | 文档频率 (df) | 倒排表(文档ID: [位置序号]) |
|---|---|---|
| “辅助” | 1 | 001: [1] |
| “英雄” | 2 | 001: [2], 002: [2] |
| “自己” | 1 | 001: [3] |
| “武将” | 1 | 001: [4] |
| “增伤” | 1 | 001: [5] |
| “敌人” | 1 | 001: [6] |
| “减防” | 1 | 001: [7] |
| “输出” | 1 | 002: [1] |
| “主要” | 1 | 002: [3] |
| “单体” | 1 | 002: [4] |
| “伤害” | 1 | 002: [5] |
查询 “辅助的英雄”,分词为 [“辅助”, “英雄”],于是分条查找。”辅助” 的结果为 001,”英雄” 的结果为 001 和 002。最后按照搜索的筛选取其交集或并集即可。
ES 中正常的文档数据会被序列化成 json 格式后存储在 ES 中。而索引是相同类型的文档的集合,而在表中一般是一个表。在数据库中称为约束的,在 ES 中称为映射。数据库中的列在 ES 中称为字段 (Field)。ES 使用 DSL 这种 json 风格的请求语句来操作,实现 CRUD。ES 的调用通过发 HTTP 请求实现。
文档操作
mapping 类型
mapping 是对索引库中文档的约束,常见的 mapping 属性包括
- type 数据类型
ES 中的基本数值类型与布尔值和 Java 是一样的(因为 ES 的底层就是拿 Java 写的)。
对于字符串,ES 可将其分为 text(可分词的文本)和 keyword(精确值,不可分词)。
还有日期 date 和对象 object 类型。
若出现数组,则表示其可能的取值,其数据类型是数组中元素对应的类型。
两种地理坐标的数据类型:geo_point(由经纬度确定的一个点)和 geo_shape(由经纬度组成的图形)。 - index 是否创建索引,默认为 true,设置为 false 时则不为该字段创建倒排索引。
- analyzer 分词器。只和 text 配合使用。
- properties 指定该字段的子字段。
索引库的 CRUD
按照上面 mapping 的不同属性,我们可以创建一个索引库
1 | |
查看索引库只需要将请求换成 GET,删除索引库只需要将请求换成 DELETE。
1 | |
而直接修改索引库的操作是不允许的(索引库不允许修改),只能新增新的字段。
1 | |
文档 CRUD
新增文档时,若没有指定文档 id,ES 会随机生成一个 id,因此最好还是自己指定一个 id(如例子中的 1)。
1 | |
定义主键时,都使用字符串类型。不分词,因此最后为 keyword。
查询文档则是使用 GET 请求。同理删除文档使用 DELETE 请求。删除时只是进行逻辑删除,并将版本号 +1。
1 | |
更新文档时,有两种修改方式。一种是全量修改,用法是将新增文档的请求改为 PUT,这样会删除旧文档,添加新文档。另一种是增量修改,只修改指定字段的值。以下是增量修改的例子
1 | |
杂记
- 使用
copy_to属性将当前字段拷贝到指定字段,相当于关系型数据库的联合索引,以支持在同一个搜索引擎中搜索多种类型的值的功能。 - 一般在 Java 中使用 RestClient 操作索引库。
DSL 查询
一般的查询语法如下
1 | |
查询所有
查询所有的数据。由于没有查询条件,因此该部分置空。
1 | |
全文检索查询
对于用户输入的内容分词后搜索。
match 即普通的查询。其中 FIELD 是搜索的字段,TEXT 是搜索的内容。
1 | |
而 multi_match 允许同时对一个 TEXT 查询多个 FIELD。
精确查询
查找 keyword 时的操作,适用于搜索日期、布尔值等类型。
term 查询用于按照词条来精确查询。
range 按照值的范围查询(如数字、日期等)。
地理查询
按照经纬度查询,即查询附近的酒店。
geo_bounding_box 查询 gro_point 值落在某个矩形范围内的所有文档。
geo_distance 查询 gro_point 值落在某个圆形范围内的所有文档。
复合查询
将简单查询组合起来,实现更复杂的查询逻辑
function score 算分函数,控制文档相关性打分,以控制文档排名。一般而言文档结果会按照搜索词的关联度打分,返回结果时按照分值降序排列。
一般情况下,算分值按照 TF (词条频率)算法来计算,即词条出现次数和文档中词条总数的比值。
然而,为了减少相同词汇的权重,增加相异但符合的词汇的权重,ES 早期(5.0前)采用了 TF-IDF 算法,其中 IDF 表示逆文档频率
$$
\text{IDF} = \log(\frac{文档总数}{包含词条的文档总数})\quad \text{score} = \sum^n_i\text{TF}\times \text{IDF}
$$
目前的 ES 主要采用 BM25 算法,计算速度较快,受词频影响较少,且可以通过调参来实现不同的查询需求。
$$
\text{score}(d, q) = \sum_{t \in q} \text{IDF}(t) \cdot \frac{\text{TF}(t, d) \cdot (k_1 + 1)}{\text{TF}(t, d) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{\text{avgdl}})}
$$
- $|d|$ 为文档字段的长度。
- $\text{avgdl}$ 为索引中所有文档的平均字段长度。
- $k_1$ 为控制词频饱和度的参数(默认 1.2)。
- $b$ 为控制字段归一化的参数(默认为 0.75)。
以下的示例中,我们给某个 id 的文档增加权重,从而排到最前面。
1 | |
常见的算分函数为
weight给一个常量值作为函数结果field_value_score用文档中的某一个字段值作为函数结果random_score随机结果script_score自定义计算公式
常见的加权模式有 multiply(默认) add avg max min replace 几种。
boolean query 是一个或多个查询子句的集合。常见的组合方式有
must与should或must_not非filter必须匹配,不参与算分
ES 的过滤性查询会放到缓存里面,在下一次查询时会进一步提升性能。
1 | |
搜索结果处理
排序
可以对 keyword 类型、数值类型、地理坐标类型、日期类型进行排序。使用 sort 字句处理。
分页
ES 默认情况下只返回前 10 的数据,如果要查询更多数据就需要修改分页参数。使用 from 和 size 字句处理。ES 设定结果集查询的上限是 10000。
在 ES 集群中,每一片 ES 集群中的数据会不一样。但不同分片中的排序和总排序可能会不一样。ES 提供了两种方案
- search after 分页时需要排序,即从上一次的排序值开始,查询下一页的数据。官方推荐。
- scroll 将排序数据形成快照,保存在内存。
高亮
即把搜索结果中的关键字突出显示。使用 highlight 关键字进行高亮标记。
1 | |
数据聚合
集合即 SQL 中的 group by 功能。
1 | |
要是要实现 Metric 聚合(即计算总和、平均值这些),则需要定义子聚合,在分组后,对每组进行计算。