MQ 的使用
参考文献
- https://rabbitmq.org.cn/tutorials
- https://javabetter.cn/sidebar/sanfene/rocketmq.html
- https://www.bilibili.com/video/BV1h94y1Q7Xg
消息队列是一种用于在应用程序之间传递消息的通信机制。它可以异步地将消息从一个应用程序发送到另一个应用程序,以实现解耦、异步处理和削峰填谷等功能。
目前常用的 MQ 有三种
| 特性维度 | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|
| 语言 | Erlang | Java | Scala & Java |
| 吞吐量 | 中,万级到十万级 QPS | 高,十万到百万级 QPS | 极高,百万级以上 QPS |
| 消息顺序 | 单个队列保证顺序,但若一个队列有多个消费者,顺序无法保证 | 严格保证顺序消息(需配合 MessageQueue 选择策略) | 保证分区内消息顺序 |
| 消息可靠性 | 很高,支持生产者确认、消费者确认、消息持久化 | 很高,支持同步/异步刷盘、主从同步/异步复制 | 高,通过 ACK 机制、ISR 副本同步机制保证 |
| 消息传递语义 | 支持 At Most Once、At Least Once | 支持 At Most Once、At Least Once | 主要支持 At Least Once,通过幂等生产者 + 事务实现 Exactly Once |
| 延迟 | 低,通常在微秒到毫秒级 | 低,毫秒级 | 较高,采用拉取模式,并且通过批量压缩来优化吞吐量,通常导致毫秒到秒级的延迟 |
| 事务消息 | 支持,但性能较差 | 原生支持,通过半消息 + 事务回查实现 | 支持,但相对较重 |
| 回溯消费 | 不支持,消费被确认即被删除 | 支持,可按时间戳或位点回溯消费 | 原生支持,消费者可重置偏移量到任意位置重新消费 |
| 协议 | AMQP、MQTT、STOMP | 自定义协议(Remoting),基于 Netty 长连接 | 自定义协议,基于 TCP |
| 应用 | 对延迟敏感,需要复杂路由的场景 | 电商/金融等核心交易系统 | 日志聚合、流式处理、网站活动追踪、实时计算等 |
以下将通过 spring AMQP 来实现 MQ 的各种功能。
相关术语
- Message
消息是消息队列中传输和存储的最小数据单元。一条消息通常包含- 业务的主体 如一串字符串
- 及其系统属性 如 Key (消息键,用于查找)、Tag (消息标签,用于过滤)、Message Id (用于标识) 等
- Topic
主题是消息的逻辑分类或集合。生产者将消息发送到某个主题,消费者从某个主题拉取信息。如一个电商系统的order_topicuser_topic等。 - Queue
Topic 在物理上的分区/分片。一个 Topic 下包含一个或多个 Queue。消息实际上存储在 Queue 中而非 Topic 中。 - Offset
Offset 是消息在 Queue 中的位置标识,可以将其理解为一个自增的、连续的序列号。 - Consumer Group
消费者组是消费者的一个逻辑组。每个消费者组都消费主题中一份完整的消息。不同消费者组之间的消费进度彼此不受影响。
- 生产者将一条带有 Tag 的信息的 Message 发送到指定的 Topic
- 消费系统根据负载均衡的策略,将这条 Message 存入 Topic 下的某个 Queue,并赋予它一个 Offset
- 消费者组中的多个消费者示例共同订阅 Topic,系统将不同的 Queue 下的数据按照规则分配给不同的 Consumer。
消费模式
作为一种 broker,消息队列用于接收和广播数据,一般分为以下两种消费模式
- 集群消费,一个消费者组共同能一个主题的多个队列,一个队列只会被一个消费者消费,默认情况下就是集群消费。若某个消费者挂掉,组内其他消费者会接替挂掉的消费者继续消费
- 广播消费,会给消费者组中的每一个消费者继续消费
Rabbit MQ
消息的生命周期
- 创建一个消息队列时有以下可选属性
durable持久化,布尔值,true Rabbit MQ 服务器重启后是否存在exclusive非排他,布尔值,true 时只能被创建它的连接使用autoDelete自动删除,布尔值,true 则当最后一个消费者取消订阅时自动删除
- 如果需要在多个 worker 中进行分布式消费。 work queues (工作队列)的主要思想是, 避免任务密集任务等待,而是直接发送。在默认情况下,Rabbit MQ 会轮询分发信息到不同的队列中。
消息确认
若消费者开始一个时间很长的任务,并且在完成前就异常终止了,但 rabbit mq 默认情况下在发送完信息就删除了,从而导致无法回滚。因此需要一个确认机制来保证消息有结果。
Rabbit MQ 主要提供了两种消息确认模式
- 自动确认。模式为
autoAck = true。当消费者成功接收到一条消息后(或者说是 Rabbit MQ 将消息发送到消费者的 TCP 套接字后),Rabbit MQ 会立即在内部将这条消息标记为已投递并立即删除。该方法吞吐量高,但风险极高,适合在对消息丢失不敏感,且处理速度非常快的场景。 - 手动确认。模式为
autoAck = false。当消费者接收到并成功处理完一条消息后,它必须显式向 Rabbit MQ 服务器发送一条确认指令。这样就可以保证其安全可靠了。
在手动确认的情况下,消费者可以向 Rabbit MQ 发送两种命令
- 肯定确认
channel.basicAck(deliveryTag, multiple)
deliveryTag指消息的唯一标识 ID,在同一个 Channel 内单调递增;multiple若为 true,则表示确认所有比当前deliveryTag小的消息,否则只确认这条消息。 - 否定确认
channel.basicNack(deliveryTag, multiple, requeue)
若requeue为 true,Rabbit MQ 会将该消息重新放回队列,否则会直接丢弃该消息。
发布订阅机制
Spring AMQP 中,发布订阅的模型通常使用 Fanout Exchange (扇出交换机)实现。
- 在配置类中,除了声明队列外,还需要声明 Fanout Exchange。
- 在发送信息时,发送的对象就变了,生产者直接向路由发送信息。
- 消费者没有变化。
匿名队列可以实现处理临时信息的功能, 可灵活实现扩容机制, 其核心实现特点:
- Exchange 和队列绑定时, 绑定键使用方法名, 而非队列名
- 创建队列时的 Bean 是唯一的, 但绑定使用的方法不唯一
- 使用时, 引用的是队列 Bean, 而非固定的队列名称
路由
可以发现,目前的路由都是通过不同的种类的 Exchange 实现。Rabbit MQ 提供了多种 Exchange 类型,每种都有不同的路由机制和适应场景
| Exchange 类型 | 路由机制 | 绑定方式 | 性能 | 适用场景 |
|---|---|---|---|---|
| Direct 直连交换机 | 精确匹配 | 队列绑定指定路由键 | 高 | 点对点的任务分发 |
| Fanout 扇出交换机 | 广播到所有队列 | 不需要路由键 | 高 | 发布订阅,广播通知 |
| Topic 主题交换机 | 模式匹配路由键 | 支持通配符 | 中 | 灵活路由、消息分类 |
| Headers 头交换机 | 消息头匹配 | 基于 header 属性 | 低 | 复杂条件路由 |
Kafka
OPPO 后端工程师 - 实习, 二面
结构
在 Kafka 中,同一个消息通常存在同一个 topic 下,而一个 topic 下分有多个 partition (分区)。每一个分区是一个线性增长的不可变的提交日志。消息存储到分区后即不可变更。Kafka 会为每一个消息提供一个偏移量,以记录每条消息的位置。
每一条消息都是一个键值对,若键为空,则 Kafka 会以轮询的方式放到每一个分区中;若键不为空,则 Kafka 会将消息放到符合条件的分区中(根据键的哈希值选择分区)。
可以通过设置 replication-factor 的数量,来指定一个分区的副本数量。这样,一旦主分区宕机,备份也可以立刻顶上,以实现高可用。
消费模型
一个分区中的数据不能被一个消费者组中的多个消费者同时消费。通过合理分配消费者和消费者组,可以实现发布订阅模式和点对点模式。
同一个生产者发送到同一分区的消息,先发送的 offset 肯定比后发送的 offset 小。同一个生产者发送到不同分区内的消息,其消息顺序无法保证。同理,对于消费者,Kafka 也只能保证分区内的消息顺序。
消息传递语义
Kafka 提供了三种消息传递语义
- 最多一次:消息可能会丢失,永远不重复发送
- 最少一次:消息不会丢失,但可能会重复
- 精确一次:保证消息被传递到服务端且在服务端不重复
在最多一次的情况下,消费者先提交消费位置,再读取消息,即使读取失败,下次读取的偏移量也不一样了;在最少一次的情况下,消费者先读取消息,再提交消费位置,若读取或提交失败,则再次读取一样的数据。
发送与消费流程
在通过 send() 方法异步发送时,生产者处会为每一个分区建立一个缓存,用于存放消息。若消息已发送到缓冲区则返回结果。而后台的线程则将缓冲区的消息发送给服务端。若需要实现同步发送,则需要接收 send 方法返回 Future<RecordMetadata> 数据并调用 get() 方法。
设置 linger.ms (发送等待时间,单位为毫秒),batch.size (发送单批的字节大小) 来实现批量发送。当二者满足任一条件时则会发送。
设置 acks 为 all 则说明每一条消息都需要所有副本确认,为 0 则说明不需要确认,为 1 则需要 leader 确认。
要实现精确一次语义,需要设置 enable.idempotence 参数值为 true,且 acks 为 all。
事务
Kafka 默认的 isolation.level,即隔离级别为读未提交。这可能会导致读到未提交的事务消息。需要自己设置隔离级别为 read_committed 以避免此问题。
为什么吞吐量高
结合以上的用法, 我们可以推测出 Kafka 高吞吐量的原因.
- 每次都先放缓存再刷盘, 避免了直接写入磁盘的开销.
- 每个分区的消费者数量不能超过分区数, 且一个分区中的数据不能被多个消费者同时消费, 否则会导致消息积压.
- 可以设置批量发送, 进一步提高吞吐量.
Rocket MQ
由于本人其实没用过 Rocket MQ, 因此这里主要是借 Rocket MQ 来归纳一下消息队列的相关概念.
消息可用性保证
消息可能在生产、存储、消费三个阶段丢失:
- 生产阶段:通过同步发送 + 确认机制保证,发送失败则重试
- 存储阶段:采用同步刷盘持久化到 CommitLog,配合主从架构实现高可用
- 消费阶段:业务逻辑执行完成后再发送确认,避免提前确认导致消息丢失
消息幂等与去重
Rocket MQ 能保证消息一定能投递,且不丢失,但无法保证消息不重复消费。但不能保证幂等性。因此在业务端需要做好去重功能,如生成全局唯一 id 等。
消息过滤
常用的消息过滤有三种:根据 Tag 过滤、使用 SQL 表达式过滤和使用 Filter Server 过滤。
使用 Tag 过滤是更常见的方法,用起来高效简单
1 | |
而 SQL 表达式则更加灵活
1 | |
分布式消息事务和半消息
半消息指暂时还不能被消费者消费的信息,生产者成功发送到 broker 的消息,此消息被标记为”暂不可投递“的状态,只有等生产端执行完本地事务并经过二次确认后,消费者才能消费此条消息。
依赖半消息,就可以实现分布式消息事务,其中的关键在于二次确认和消息回查。
- 生产者发送半消息,并执行本地事务
- 生产者向 MQ Server 发送一条半消息。MQ 收到后,将其持久化存储,但不会将其投递到目标 Topic 中。MQ 返回 ACK 相应给生产者。
- 生产者收到半消息发送成功相应后,开始执行本地数据库事务。本地事务执行完成后,生产者会向 MQ 发送提交会回滚指令。
- 若生产者在执行完本地事务后,发送指令前,发生了宕机合伙网络异常,此时的半消息就处于未知状态。Rocket MQ 引入了事务回查机制。MQ 会定期扫描所有处于“半消息”状态且超时未确认的消息。对于每条需要回查的消息,MQ 会回调消息中指定的生产者应用程序的一个接口。生产者会对该消息检查本地事务的执行结果,并发送提交或回调指令。
死信队列
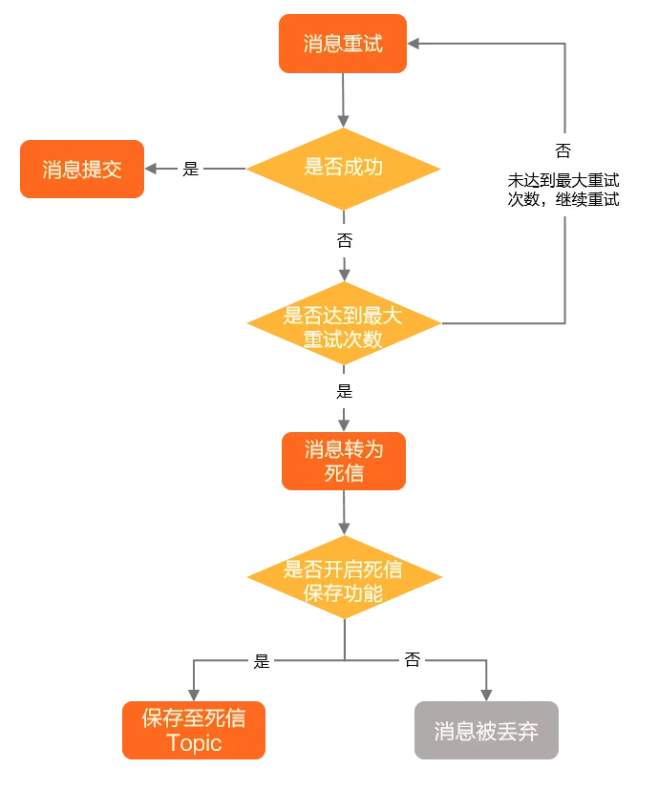
若消费者在处理消息时发生异常,且达到了最大重试次数,这条消息就成了死信。当消费失败的原因排查并解决后,就可以重发这条死信消息,让消费者重新消费;如果暂时无法处理,可以将死信进行保存或直接丢弃。
工作流程
Rocket MQ 作为一个分布式消息队列,兼具消息队列和分布式系统的功能。作为消息队列,它只是一个队列,对应生产者、broker、消费者;作为分布式系统,它就有服务端、客户端、注册中心,对应 broker、生产/消费者、NameServer。
- broker 在启动时去向所有的 NameServer 注册,并保持长连接,每 30s 发一次心跳
- 生产者在发送信息时从 NameServer 中获取 broker 服务器地址,按照负载均衡算法选择一台服务器发送
- 消费者在接收信息时从 NameServer 中获取 broker 地址,然后通过 Push 或 Pull 模式消费消息
文件读写
MQ 对文件读写有很高的速度要求。因此对文件读写的机制也和一般程序不同。
Rocket MQ 中 Consume Queue 存储的数据较少,并且是顺序读取,因此在 page cache 的预读取作用下,Consume Queue 文件的读性能几乎接近读内存,即使在有消息堆积的情况下也不会影响性能。而对于 Commit log 中存储的文件,当消费者根据 Consume Queue 的索引去拉取消息内容时,会访问 Commit Log 中的不同位置。这种访问模式在逻辑上是随机的。然而,由于消息在 Commit Log 中是顺序写入的,其在物理磁盘上的分布相对连续,加之 OS 的 PageCache 和 SSD 硬盘的高 IOPS,使得这种读取模式的性能依然很高,其影响远没有在机械硬盘上传统随机读写那样严重。
此外,Rocket MQ 主要通过 MappedByteBuffer 对文件进行读写操作。其中,利用了 mmap 系统调用,将磁盘文件直接映射到进程的虚拟内存地址空间。这样,应用程序对这段内存的读写操作,就由操作系统在后台自动转换为对文件的读写,从而避免了使用传统 read/write 系统调用引发的用户态和内核态间的数据拷贝,极大提高了文件效率.
此外, 由于没有更改机制, 因此相比关系型数据库, 也就不需要先写 undo log 了, 因此此处消息队列本质上是在写 redo log.