二叉树 二叉树中序遍历 递归
1 2 3 4 5 6 7 8 9 10 11 class Solution {public List<Integer> inorderTraversal (TreeNode root) {new ArrayList <>();if (root == null )return new ArrayList <Integer>();return list;
迭代. 存储一个栈。栈每次固定弹出一个。在此题中,放入的条件为先放入左子树,读取栈数据,再放入其右子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public List<Integer> inorderTraversal (TreeNode root) {new ArrayList <Integer>();new LinkedList <TreeNode>();while (root != null || !stk.isEmpty()) {while (root != null ) {return res;
二叉树的最大深度 也无需多言
1 2 3 4 5 class Solution {public int maxDepth (TreeNode root) {return root == null ? 0 : Math.max(maxDepth(root.left) + 1 , maxDepth(root.right) + 1 );
也可以做一遍层序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public int maxDepth (TreeNode root) {if (root == null )return 0 ;new LinkedList <TreeNode>();int ans = 0 ;while (!queue.isEmpty()) {int size = queue.size();while (size > 0 ) {TreeNode node = queue.poll();if (node.left != null )if (node.right != null )return ans;
翻转二叉树 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
无需多言
1 2 3 4 5 6 7 8 9 10 class Solution {public TreeNode invertTree (TreeNode root) {if (root == null )return null ;TreeNode temp = invertTree(root.left);return root;
只要能用递归的二叉树都不算难,并且递归都能用队列迭代来替代实现。
对称二叉树 给你一个二叉树的根节点 root , 检查它是否轴对称。
示例:root = [1,2,2,3,4,4,3]true
要查看这棵树是不是对称的二叉树, 就要看其左边的左子树和右边的右子树是否对称. 因此可以不断递归.
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public boolean isSymmetric (TreeNode root) {return check(root.left, root.right);public boolean check (TreeNode p, TreeNode q) {if (p == null && q == null )return true ;if (p == null || q == null )return false ;return p.val == q.val && check(p.left, q.right) && check(p.right, q.left);
使用迭代时,需要把根节点入队两个并提取两个节点,最后比较他们的值。然后将两个节点的左右子节点按相反的顺序插入队列中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public boolean isSymmetric (TreeNode root) {return check(root, root);public boolean check (TreeNode u, TreeNode v) {new LinkedList <TreeNode>();while (!q.isEmpty()) {if (u == null && v == null )continue ;if ((u == null || v == null ) || (u.val != v.val))return false ;return true ;
二叉树的直径 给你一棵二叉树的根节点,返回该树的直径 。直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
示例:root = [1,2,3,4,5]33 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。
任意一条路径的长度为该路径经过的节点数减一,而任一路径均可以看作由某个节点为起点,从其左儿子和右儿子向下遍历的路径拼接得到。
于是,某节点为起点的路径纪念馆过节点数的最大值为$L+R+1$。而二叉树直径就是所有结点路径的最大值减一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {int ans;public int diameterOfBinaryTree (TreeNode root) {1 ;return ans - 1 ;public int depth (TreeNode node) {if (node == null )return 0 ;int L = depth(node.left);int R = depth(node.right);1 );return Math.max(L, R) + 1 ;
其中的ans为路径的最大值。
二叉树层序遍历 参考求最大高度的迭代代码 即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public List<List<Integer>> levelOrder (TreeNode root) {if (root == null )return new ArrayList <>();new ArrayList <>();new LinkedList <>();while (!queue.isEmpty()) {int size = queue.size();new ArrayList <>();while (size > 0 ) {TreeNode node = queue.poll();if (node.left != null )if (node.right != null )return ans;
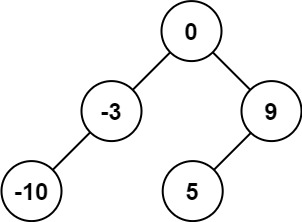
将有序数组转换为二叉搜索树 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。
示例:nums = [-10,-3,0,5,9][0,-3,9,-10,null,5][0,-10,5,null,-3,null,9] 也将被视为正确答案
平衡二叉树的子树也一定是平衡二叉树,因此可以通过子数列递归实现。就我的通过代码来看,时间最快但空间使用率吓人
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public TreeNode sortedArrayToBST (int [] nums) {int length = nums.length, middle = length / 2 ;TreeNode ans = new TreeNode (nums[middle]);if (middle != 0 ) {int [] left = Arrays.copyOfRange(nums, 0 , middle);if (middle != length - 1 ) {int [] right = Arrays.copyOfRange(nums, middle + 1 , length);return ans;
按照题解,选择中间靠左、中间靠右、任意数作为根节点都有对应的BST,此处仅选择第一种。此时的根节点下标为(整数除法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public TreeNode sortedArrayToBST (int [] nums) {return helper(nums, 0 , nums.length - 1 );public TreeNode helper (int [] nums, int left, int right) {if (left > right)return null ;int mid = (left + right) / 2 ;TreeNode root = new TreeNode (nums[mid]);1 );1 , right);return root;
验证二叉搜索树 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
参考视频
前序遍历 每一次到达非叶子节点时, 就更新一次节点理应存在的节点值. 对于根节点而言, 其范围为 $(-\infty,\infty)$. 每次往左子树遍历时更新右上限, 往右子树遍历时更新左下限. 如果该节点的值超过了区间的范围, 那么这棵树就不是二叉搜索树.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public boolean isValidBST (TreeNode root) {return isValidBST(root, Long.MIN_VALUE, Long.MAX_VALUE);private boolean isValidBST (TreeNode node, long left, long right) {if (node == null ) {return true ;long x = node.val;return left < x && x < right &&
中序遍历 不难发现二叉搜索树的中序遍历就是递增数组, 因此将其中序遍历一遍, 看其单调性就是结果. 以下是官解的做法. 其实此处的栈略显多余, 往方法外定义好存储前一个数的变量就好.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public boolean isValidBST (TreeNode root) {new LinkedList <TreeNode>();double inorder = -Double.MAX_VALUE;while (!stack.isEmpty() || root != null ) {while (root != null ) {if (root.val <= inorder) {return false ;return true ;
后序遍历 此处的思路和前序遍历是一致的. 只是赋值为 $(-\infty,\infty)$ 的节点从根节点变成了叶子节点. dfs 用于返回子树的最小值和最大值.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public boolean isValidBST (TreeNode root) {return dfs(root)[1 ] != Long.MAX_VALUE;private long [] dfs(TreeNode node) {if (node == null ) {return new long []{Long.MAX_VALUE, Long.MIN_VALUE};long [] left = dfs(node.left);long [] right = dfs(node.right);long x = node.val;if (x <= left[1 ] || x >= right[0 ]) {return new long []{Long.MIN_VALUE, Long.MAX_VALUE};return new long []{Math.min(left[0 ], x), Math.max(right[1 ], x)};
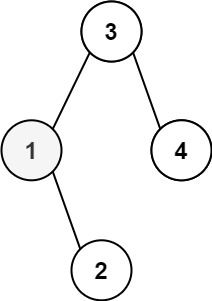
二叉搜索树中第K小的元素 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。
示例:root = [3,1,4,null,2], k = 11
牢记BST的中序遍历呈升序排列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public int kthSmallest (TreeNode root, int k) {new LinkedList <>();int counter = 1 ;while (root != null || !stack.isEmpty()) {while (root != null ) {if (counter == k)return root.val;return 0 ;
二叉树的右视图 给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例:root = [1,2,3,null,5,null,4][1,3,4]
官方题解是基于dfs的递归实现,我们总是先访问右子树,这样出来的就是最右边的结点了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {public List<Integer> rightSideView (TreeNode root) {new HashMap <Integer, Integer>();int max_depth = -1 ;new LinkedList <TreeNode>();new LinkedList <Integer>();0 );while (!nodeStack.isEmpty()) {TreeNode node = nodeStack.pop();int depth = depthStack.pop();if (node != null ) {if (!rightmostValueAtDepth.containsKey(depth))1 );1 );new ArrayList <Integer>();for (int depth = 0 ; depth <= max_depth; depth++)return rightView;
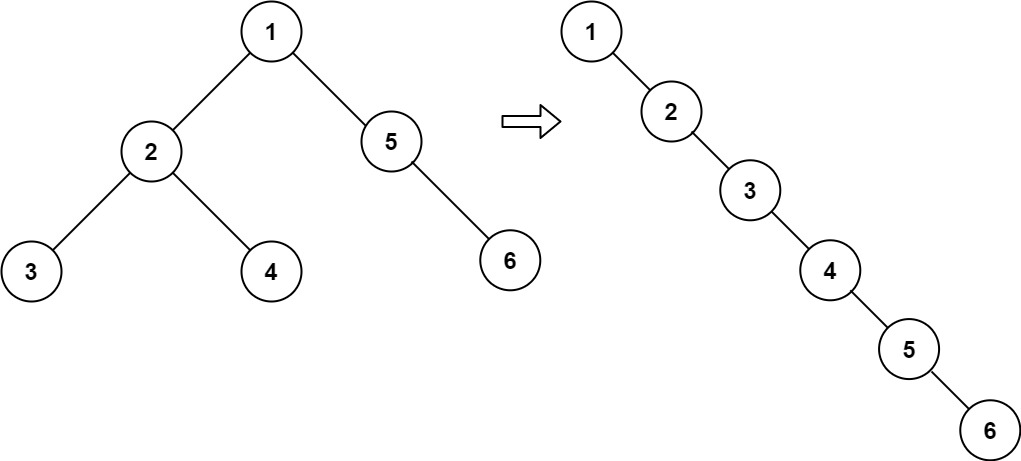
二叉树展开为链表 给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例:root = [1,2,5,3,4,null,6][1,null,2,null,3,null,4,null,5,null,6]
简简单单的递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public void flatten (TreeNode root) {if (root == null )return ;if (root.left == null )return ;TreeNode temp = root.left, right = root.right;while (temp.right != null )null ;
最简单的办法就是先序遍历,然后在先序遍历的过程中一个个加链表的值。如果执意要实现$O(1)$空间复杂度的话,就需要寻找前驱节点。
对于当前节点,若左节点不为空,则寻找左子树最右边的节点,作为前驱节点
当前节点的右子节点赋给前驱节点的右子节点
当前节点的左子节点赋给当前节点的右子节点,左子节点赋空
继续处理下一节点(即cur移动到2)
故最后的源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public void flatten (TreeNode root) {TreeNode curr = root;while (curr != null ) {if (curr.left != null ) {TreeNode next = curr.left;TreeNode pre = next;while (pre.right != null ) {null ;
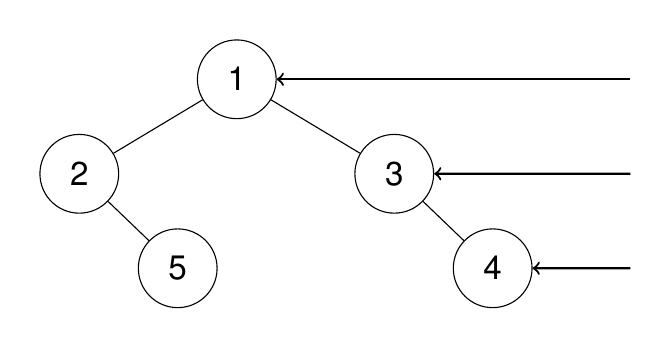
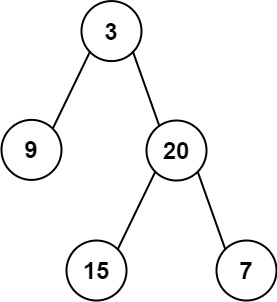
从前序与中序遍历序列构造二叉树 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例:preorder = [3,9,20,15,7], inorder = [9,3,15,20,7][3,9,20,null,null,15,7]
先序遍历的第一个数一定是根节点,中序遍历中根节点的左边一定在左子树上,而这篇数据在先序遍历中也一定是连续的,因此可以通过某种手段将这两个序列分成两半,分别对应左子树和右子树。然后通过递归或迭代生成对应结果。
先前写的C++的代码。该题不难,主要是比较复杂。学校数据结构oj也有原题,但给的参数是数组,数组的分割和参数传递极其简单,算是给降难度了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public :TreeNode* buildTree (vector<int >& preorder, vector<int >& inorder) {if (preorder.empty () || inorder.empty ())return nullptr ;int root_val = preorder[0 ];auto it_in = inorder.begin (), it_pre = preorder.begin () + 1 ;for (; *it_in != root_val; ++it_in);int > left_inorder, right_inorder, left_preorder, right_preorder;if (it_in != inorder.begin ())insert (left_inorder.end (), inorder.begin (), it_in);if (it_in != inorder.end () - 1 )insert (right_inorder.end (), it_in + 1 , inorder.end ());insert (left_preorder.end (), it_pre, it_pre + left_inorder.size ());if (it_pre != preorder.end ())insert (right_preorder.end (), it_pre + left_inorder.size (), preorder.end ());return new TreeNode (root_val, buildTree (left_preorder, left_inorder), buildTree (right_preorder, right_inorder));
在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。在此后构造二叉树的过程中,我们就只需要 $O(1)$ 的时间对根节点进行定位了。
以下为递归法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {private Map<Integer, Integer> indexMap;public TreeNode myBuildTree (int [] preorder, int [] inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) {if (preorder_left > preorder_right)return null ;int preorder_root = preorder_left;int inorder_root = indexMap.get(preorder[preorder_root]);TreeNode root = new TreeNode (preorder[preorder_root]);int size_left_subtree = inorder_root - inorder_left;1 , preorder_left + size_left_subtree, inorder_left, inorder_root - 1 );1 , preorder_right, inorder_root + 1 , inorder_right);return root;public TreeNode buildTree (int [] preorder, int [] inorder) {int n = preorder.length;new HashMap <Integer, Integer>();for (int i = 0 ; i < n; i++)return myBuildTree(preorder, inorder, 0 , n - 1 , 0 , n - 1 );
以下为迭代法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public TreeNode buildTree (int [] preorder, int [] inorder) {if (preorder == null || preorder.length == 0 )return null ;TreeNode root = new TreeNode (preorder[0 ]);new LinkedList <TreeNode>();int inorderIndex = 0 ;for (int i = 1 ; i < preorder.length; i++) {int preorderVal = preorder[i];TreeNode node = stack.peek();if (node.val != inorder[inorderIndex]) {new TreeNode (preorderVal);else {while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) {new TreeNode (preorderVal);return root;
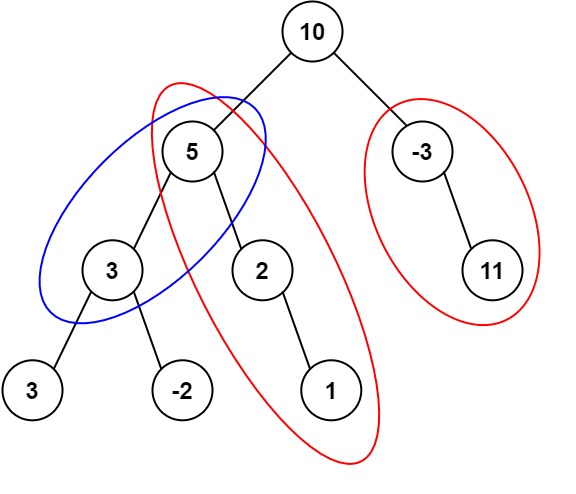
路径总和III 给定一个二叉树根节点root,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 838 的路径有 3 条,如图所示。
深度优先搜索 使用dfs递归肯定是最自然的,但怎么实现是个问题。太简单的递归容易多算情况。
我们首先定义rootSum(p,val)表示以节点p为起点向下且满足路径总和为val的路径数目(而非使用自带函数递归),对二叉树上每个节点p求出rootSum(p,val),然后对这些路径数目求合就是结果。
对节点p求rootSum(p,targetSum)时,以当前节点p为目标路径的起点递归向下进行搜索。假设当前的节点p的值为val,我们对左子树合右子树进行递归搜索,对其左孩子节点求出rootSum(p.left,targetSum - val),右孩子同理。最后求和。同时我们还需要判断一下节点本身是否刚好等于targetSum。
采用递归遍历二叉树每个节点p,求rootSum(p,val),然后将每个节点所有求的值进行相加求和并返回。
简单来说,pathSum的递归是对每一条可能的不同路径进行递归,而rootSum的递归是对某条特定路径进行求值。由此可以避免出现求多情况的可能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public int pathSum (TreeNode root, long targetSum) {if (root == null )return 0 ;int ret = rootSum(root, targetSum);return ret;public int rootSum (TreeNode root, long targetSum) {int ret = 0 ;if (root == null )return 0 ;int val = root.val;if (val == targetSum)return ret;
前缀和 此此方法可以把时间复杂度由 $O(n^2)$ 降到 $O(n)$。
先序遍历二叉树,记录下根节点到当前节点的路径上,除当前节点意外所有节点的前缀和。在已保存的路径前缀和中查找是否存在前缀和刚好等于当前节点到根节点的前缀和
空路径也需要保存预先处理一下。因为空路径不经过任何节点,因此它的前缀和为0
其他路径的前缀和由节点到根节点的数据相减获得
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public int pathSum (TreeNode root, int targetSum) {new HashMap <Long, Integer>();0L , 1 );return dfs(root, prefix, 0 , targetSum);public int dfs (TreeNode root, Map<Long, Integer> prefix, long curr, int targetSum) {if (root == null )return 0 ;int ret = 0 ;0 );0 ) + 1 );0 ) - 1 );return ret;
代码中的curr即为前缀和。一开始先更新前缀和数据。然后检查有多少个祖先节点满足条件(即从根节点到某个祖先节点的路径),赋值给ret
1 2 3 4 [ ] ----- ----- ---------- --------- ----- -----
curr - targetSum = 15 - 8 = 7
查找前缀和为7的出现次数,若结果为2,则说明存在2个不同的祖先节点,节点->当前节点的路径和为8。
二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
示例:
参考视频
经总结可以得到以下的分类状况
当前节点是空节点, 或当前节点是 p, 或当前节点是 q 时, 最近公共祖先要么在其上方, 要么就是其本身. 因此返回当前节点, 不往下递归了
左右子树都找到时, 说明最近公共祖先就是自己, 返回当前节点
只有左子树找到, 答案在左子树, 返回递归左子树的结果
只有右子树找到, 答案在右子树, 返回递归右子树的结果
都没有找到, 返回空
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) {if (root == null || root == p || root == q) {return root;TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);if (left != null && right != null ) {return root;return left != null ? left : right;
二叉树中最大的路径和 二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。路径和 是路径中各节点值的总和。给你一个二叉树的根节点 root ,返回其 最大路径和 。
递归 考虑一个函数maxGain(node),计算二叉树某个节点的最大贡献值,也就是说,以该节点为根节点的子树中,寻找以该节点为起点的一条路径,使得该路径上的节点之和最大。
空节点的最大贡献值为0
非空节点的最大贡献值等于该节点与其子节点中的最大贡献值之和(叶节点则为节点值本身)
对于以下子树
graph TD
-10-->9
-10-->20-->15
20-->7
9 15 7的最大贡献值是其本身,20的贡献值为20 + max(15,7) = 35,节点-10的最大贡献值为-10 + max(9,35) = 25。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {int maxSum = Integer.MIN_VALUE;public int maxPathSum (TreeNode root) {return maxSum;public int maxGain (TreeNode node) {if (node == null )return 0 ;int leftGain = Math.max(maxGain(node.left), 0 );int rightGain = Math.max(maxGain(node.right), 0 );int priceNewpath = node.val + leftGain + rightGain;return node.val + Math.max(leftGain, rightGain);
堆 数组中第K个最大的元素 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
快排 有关快排的内容可以看这里 a[l...q-1]中的每个元素,都小于a[q],且a[q]小于a[q+1...r]中的每个元素,因此,只要某次划分的q为倒数第k个下标的时候,我们就找到了答案。q恰好就是需要的数,就返回a[q];若q比目标下标小,就递归右区间,否则递归左区间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {int quickselect (int [] nums, int l, int r, int k) {if (l == r) return nums[k]; int x = nums[l], i = l - 1 , j = r + 1 ;while (i < j) {do i++; while (nums[i] < x);do j--; while (nums[j] > x);if (i < j){int tmp = nums[i];if (k <= j) return quickselect(nums, l, j, k);else return quickselect(nums, j + 1 , r, k);public int findKthLargest (int [] _nums, int k) {int n = _nums.length;return quickselect(_nums, 0 , n - 1 , n - k);
quickselect()函数中,第二第三个参数是数组的指定区间,最后一个参数为指定元素的索引。在入口函数findKthLargest()中,寻找的是第k大的元素在升序数组中的位置n - k。以最左元素nums[l]为基准,
初始化指针i = l - 1和j = r + 1
移动i直到找到不小于基准的元素,移动j直到找到不大于基准的元素
交换i和j的元素,确保左侧元素不大于基准,右侧元素不小于基准
这其实就是快排的过程。然后自然就是递归。但我们只需要找出对应元素即可,因此可以递归半边。若k <= j,说明目标在左半部分,只需递归左半部分即可,右边同理。
堆排 建立一个大根堆,做 $k-1$ 次删除操作后堆顶的元素就是我们要找的答案。有关堆排序的内容可以看这里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public int findKthLargest (int [] nums, int k) {int heapSize = nums.length;for (int i = nums.length - 1 ; i >= nums.length - k + 1 ; --i) {0 , i);0 , heapSize);return nums[0 ];public void buildMaxHeap (int [] a, int heapSize) {for (int i = heapSize / 2 - 1 ; i >= 0 ; --i)public void maxHeapify (int [] a, int i, int heapSize) {int l = i * 2 + 1 , r = i * 2 + 2 , largest = i;if (l < heapSize && a[l] > a[largest])if (r < heapSize && a[r] > a[largest])if (largest != i) {public void swap (int [] a, int i, int j) {int temp = a[i];
时间复杂度为 $O(n \log n)$
前K个高频元素 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。必须 优于 $O(n \log n)$ ,其中 n 是数组大小。
堆 维护一个“出现次数数组”,建立一个小顶堆,然后给这个“出现次数数组”排序。
若堆的元素个数小于k,就直接插入堆中
若堆的元素个数等于k,就检查堆顶与当前出现次数的大小,堆顶值更小时就弹出堆顶,并将当前值插入堆中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public int [] topKFrequent(int [] nums, int k) {new HashMap <Integer, Integer>();for (int num : nums)0 ) + 1 );int []> queue = new PriorityQueue <int []>(new Comparator <int []>() {public int compare (int [] m, int [] n) {return m[1 ] - n[1 ];for (Map.Entry<Integer, Integer> entry : occurrences.entrySet()) {int num = entry.getKey(), count = entry.getValue();if (queue.size() == k)if (queue.peek()[1 ] < count) {new int []{num, count});else new int []{num, count});int [] ret = new int [k];for (int i = 0 ; i < k; ++i)0 ];return ret;
PriorityQueue是一个优先队列,在Java中默认是一个小顶堆,中间的Comparator<int[]>是其优先级插队规则(按出现次数排序)Map.Entry<Integer, Integer> entry表示Map的一个键值对
快排 在进行划分时,根据k与左侧子数组的长度q - i的大小关系
若k <= q - i,则数组arr[i...r]前k大的值就等于数组arr[i...q - 1]中前k大的值
否则,数组arr[i...r]前k大的值,就等于左侧子数组的全部元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {public int [] topKFrequent(int [] nums, int k) {new HashMap <Integer, Integer>();for (int num : nums)0 ) + 1 );int []> values = new ArrayList <int []>();for (Map.Entry<Integer, Integer> entry : occurrences.entrySet()) {int num = entry.getKey(), count = entry.getValue();new int []{num, count});int [] ret = new int [k];0 , values.size() - 1 , ret, 0 , k);return ret;public void qsort (List<int []> values, int start, int end, int [] ret, int retIndex, int k) {int picked = (int ) (Math.random() * (end - start + 1 )) + start;int pivot = values.get(start)[1 ];int index = start;for (int i = start + 1 ; i <= end; i++)if (values.get(i)[1 ] >= pivot) {1 , i);if (k <= index - start)1 , ret, retIndex, k);else {for (int i = start; i <= index; i++)0 ];if (k > index - start + 1 )1 , end, ret, retIndex, k - (index - start + 1 ));
数据流的中位数 实现 MedianFinder 类:
MedianFinder() 初始化 MedianFinder 对象。void addNum(int num) 将数据流中的整数 num 添加到数据结构中。double findMedian() 返回到目前为止所有元素的中位数。与实际答案相差 $10^{-5}$ 以内的答案将被接受。
用两个优先队列queMax和queMin来存比中位数小的数和大于等于中位数的数。queMin中的数量比queMax多一个,此时中位数为queMin的队头;为偶数时中位数为两个优先队列的平均数。特别地,当累计添加的数据为0时,先将数据加到小的那半。queMin中的中位数,就将这个数添加到queMin中,否则加到queMax中。若两个堆的元素数量尽量平衡,若不平衡(相差超过1)就把多的那堆放一个数据到另一边。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class MedianFinder {public MedianFinder () {new PriorityQueue <Integer>((a, b) -> (b - a));new PriorityQueue <Integer>((a, b) -> (a - b));public void addNum (int num) {if (queMin.isEmpty() || num <= queMin.peek()) {if (queMax.size() + 1 < queMin.size())else {if (queMax.size() > queMin.size())public double findMedian () {if (queMin.size() > queMax.size())return queMin.peek();return (queMin.peek() + queMax.peek()) / 2.0 ;
非 hot 100 求根节点到叶子节点数据之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。每条从根节点到叶节点的路径都代表一个数字:例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的所有数字之和 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int sumNumbers (TreeNode root) {return dfs(root, 0 );public int dfs (TreeNode root, int prevSum) {if (root == null ) {return 0 ;int sum = prevSum * 10 + root.val;if (root.left == null && root.right == null ) {return sum;else {return dfs(root.left, sum) + dfs(root.right, sum);
![路径 [9, 4, 2, 5, 7, 8] 可以被看作以 2 为起点,从其左儿子向下遍历的路径 [2, 4, 9] 和从其右儿向下遍历的路径 [2, 5, 7, 8] 拼接得到。](explain1.jpg)